

可能会选择深度优先搜索这两种搜索算法各有其优缺点宽度优先搜索能找到最短路径搜索算法的区别,但需要消耗大量内存来存储待访问节点而深度优先搜索内存消耗相对较少,因为它不需要存储每一层级的所有节点,但在某些情况下可能找不到最短路径在实际应用中,我们会根据问题的特性和需求选择合适的搜索算法。
A star算法更是集两者之大成,结合Dijkstra的代价计算和贪婪搜索的导向性,使用启发函数hn来引导搜索,既追求最短路径又减少节点访问,灵活适应不同场景启发函数的调整,如曼哈顿对角或欧几里得距离,能根据图的移动限制和需求,平衡速度与精确度总之,选择合适的搜索算法取决于问题的特性和需求。
上溯和回溯是两种不同的搜索算法,其区别如下1 定义 上溯一般称为“逆序执行”是指从下往上搜索解空间树的过程,即从问题的最终状态往回推导,直到找到问题的初始状态上溯常用于回溯算法和规划问题 回溯是指从上往下搜索解空间树的过程,即从问题的初始状态往前推进,逐步试探求解回溯。
#160 #160 #160 #160 深度优先搜索和广度优先搜索,都是图形搜索算法,它两相似,又却不同,在应用上也被用到不同的地方这里拿一起讨论,方便比较一深度优先搜索 #160 #160 #160 #160 深度优先搜索属于图算法的一种,是一个针对图和树的遍历算法,英文缩写为DFS。
一维搜索的算法的优缺点如下优点 简单直观一维搜索算法易于理解和实现,适用于简单的问题和数据集 快速找到目标值在适用场景下,一维搜索算法能够快速定位到目标值缺点 效率较低由于一维搜索算法需要逐个比较元素,时间复杂度为O,当数据集较大时,搜索时间会显著增加 对无序数据集不友好。
dfs和bfs算法的区别是dfs是深度优先搜索,它以深度为优先进行搜索,而bfs是广度优先搜索,它以广度为优先进行搜索拓展dfs搜索通常需要更多的存储空间,而bfs则可以更快地搜索到目标,但它的空间需求更高因此,根据实际情况,可以选择合适的算法来解决问题。
2算法区别 深度优先搜索是每次从栈中弹出一个元素,搜索所有在它下一级的元素,把这些元素压入栈中并把这个元素记为它下一级元素的前驱,找到所要找的元素时结束程序广度优先搜索是每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾并把这个元素记为它下一。
而对于启发式算法,针对不同的问题,我们可以套用同一个架构来寻找答案,在这个过程中,我们只需要设计评价函数以及如何找到下一个可能解的函数等,所以启发式算法的广泛性比较高,但相对在准确度上就不一定能够达到最优,但是在实际问题中启发式算法那有着更广泛的应用。
我们继续看看何谓A*算法2初识A*算法 启发式搜索其实有很多的算法,比如局部择优搜索法最好优先搜索法等等当然A*也是这些算法都使用搜索算法的区别了启发函数,但在具体的选取最佳搜索节点时的 策略不同象局部择优搜索法,就是在搜索的过程中选取“最佳节点”后舍弃其搜索算法的区别他的兄弟节点,父亲节点,而一直得。
Vikea继续按此方式拓展InTimisoara和InZerind如果未找到目标状态,则继续对叶子结点作同样的操作2图搜索算法在图搜索算法中,在扩展的时候如果遇到已经在 explored 集合中的结点或已经在 frontier 集合中的结点,则不将该结点拓展进 frontier 集合,这也是其与树搜索算法的主要区别。
find算法的语法简洁,自动类型推导的使用使得代码更加简洁和统一示例代码auto it = stdfind, containerend, value与其他查找算法的区别find_first_of和find_end用于在两个序列间进行搜索,查找不同序列元素的匹配机制,提供了更为灵活的查找方式search算法用于查找特定模式作为子序列的首次。
语言和文化百度 主要用于中文搜索,因此对中文内容的理解更为深入百度的搜索算法更加注重中文关键词的匹配和语义理解谷歌 支持全球多种语言,因此其搜索算法更加多样化,涵盖了全球不同语言和文化的搜索需求搜索算法百度 百度的搜索算法相对更为封闭,其具体工作机制相对保密百度更注重关键词。
若节点B在边缘,而A的祖先节点也在边缘,且启发式函数的值小于A的总成本,A*算法会考虑这种情况,但不会将B作为最优解在A*算法中,启发式函数的合理选择至关重要,它影响了算法的效率和准确性此外,A*算法与Dijkstra算法有所不同,Dijkstra算法不考虑启发式信息,因此在所有节点都被访问前,它。

盲目搜索算法,也称为无信息搜索,是一种只依据预定的搜索策略进行搜索,而不考虑问题特性的方法通常适用于简单的问题求解,其中较为常见的包括宽度优先搜索算法和深度优先搜索宽度优先搜索算法BFS以队列实现,从根节点开始遍历,遍历完再按照同样的方式遍历下一层节点其优点在于能够找到最短路径。
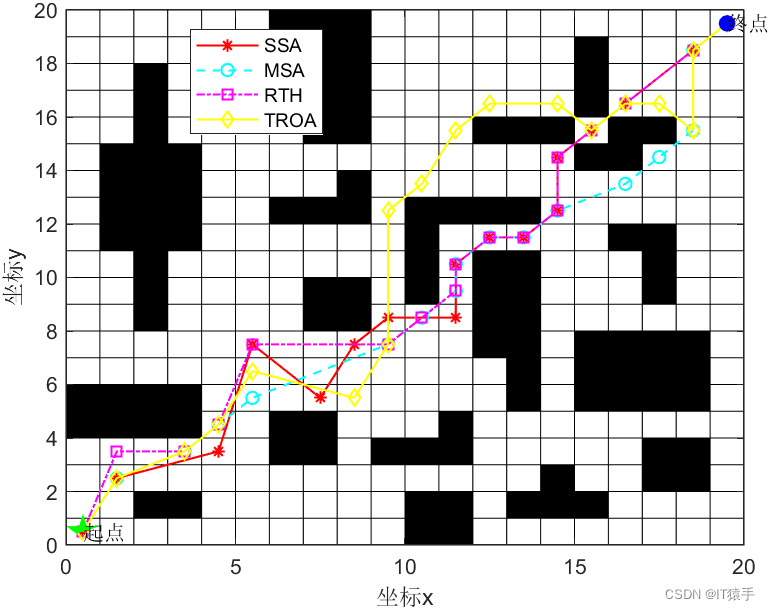
这两种算法的主要区别在于它们的搜索策略和访问顺序 深度优先算法的时间复杂度通常为OV+E,其中V是图中节点的数量,E是图中边的数量这种算法通过深度优先搜索DFS的方遍历图,它首先访问起始节点,然后探索尽可能深的分支,直到无法继续探索为止然后,它会回溯到前一个节点,继续探索其他分支。
第331节评估函数设计 评估函数依据问题的特点设计,通过权重调整来优化搜索过程具体包括Gx和Hx的计算,以及它们在Fx中的应用第4章测试与验证 通过生成测试样例,比较三种算法在不同情况下的性能实验证明启发式搜索算法在效率上优于其他方法第5章代码优化与改进 通过限制搜索。








还没有评论,来说两句吧...