

1、自回归语言模型Autoregressive Modelgpt和bert的区别, AR模型和自编码语言模型AutoEncoding Model是语言模型gpt和bert的区别的两种不同方式AR模型在预测下一个单词时,只能利用上文信息,形成单向预测这种方式适用于文本生成和机器翻译任务,如Transformer和OpenAI的GPT系列论文中的GPT模型GPT系列模型的论文标题分别为Improving。
2、在实际应用中,不同任务需要选择合适的模型AR模型适用于生成式任务,而AE模型如BERT则适用于内容理解任务,如情感分析和提取式问答同时,同时使用编码器和解码器的EncoderDecoder模型如T5BART和BigBird则适用于需要内容理解和生成的任务,如机器翻译综上所述,自回归模型与自编码模型各有优缺点。
3、2 GPT系列GPT是由OpenAI开发的一系列生成式预训练Transformer模型与BERT不同,GPT是单向的,它使用了一种称为“自回归”Autoregressive的方法,即根据前面的词来预测下一个词GPT2和GPT3是该系列的后续版本,其中GPT3具有惊人的1750亿个参数,能够生成非常连贯和高质量的文本3 T5T5。
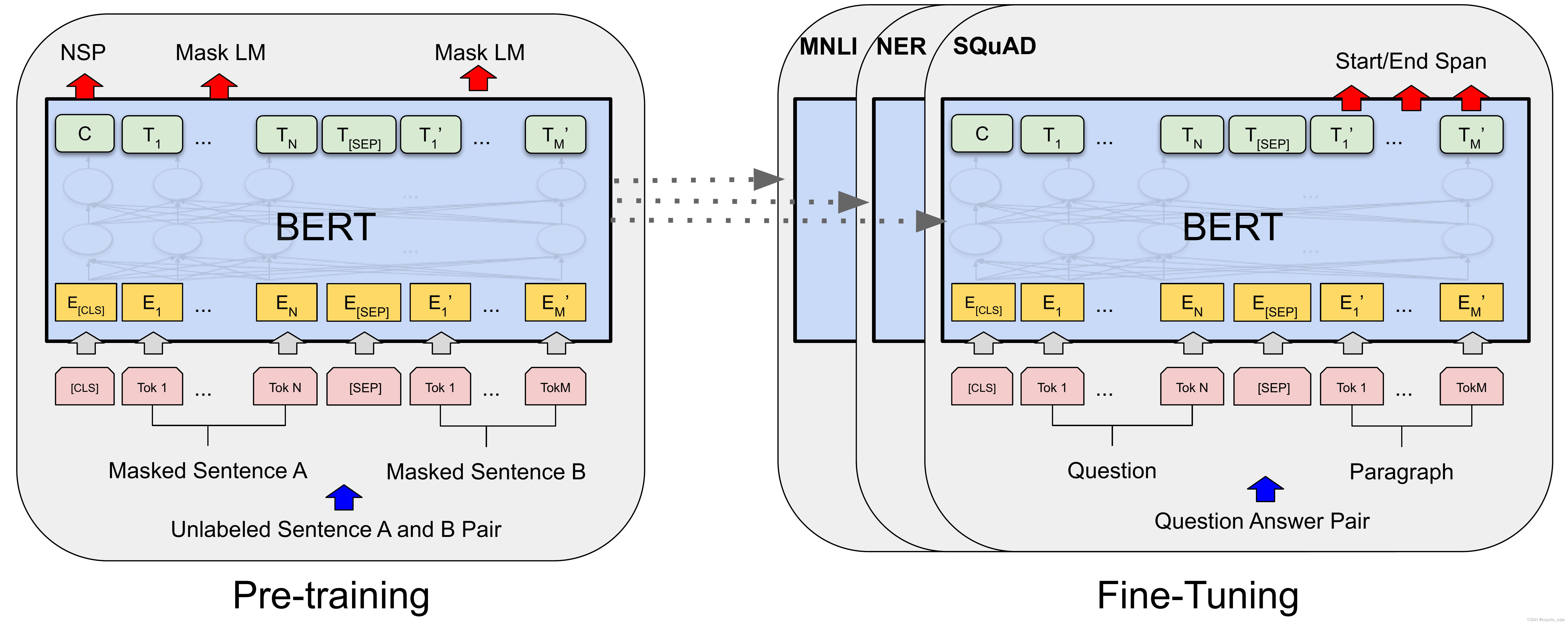
4、三者对比 模型结构BERT使用双向Transformer,GPT采用从左到右的Transformer模型,而ELMo结合独立训练的双向LSTM 预训练任务BERT通过Masked LM和Next sentence Prediction任务进行预训练GPT主要通过预测下一个词进行预训练ELMo则在上下文中预测文本序列的概率 特征学习方法BERT和GPT通过微调方法学习。
5、四BertOpenAI GPTELMo模型简单对比BERT使用双向Transformer,GPT采用从左到右的Transformer模型,而ELMo结合独立训练的双向LSTMBERT和GPT通过微调方法学习特征,ELMo则基于特征生成方法综上所述,BERTELMoGPT模型在语言处理领域各具特色,它们的原理和应用在不断推动自然语言处理技术的发展。
6、BERT训练阶段的显存占用包括模型参数输入输出和激活值测试阶段则包括模型参数输入向量和输出向量BERT的输入长度对显存占用有显著影响,显存占用为O关系此外,BERT的Batch Size和显存占用之间存在O关系GPT虽然具体数值可能因模型大小和结构而异,但显存占用的原理和BERT类似,也涉及模型参数。
7、GPT3的强大之处在于其能够理解和生成复杂的自然语言,从而在对话系统内容创作等领域具有广泛的应用前景BERT BERTBidirectional Encoder Representations from Transformers是Google开发的一种预训练语言表示模型BERT通过双向Transformer编码器对文本进行深度双向训练,从而能够更准确地捕捉文本中的上下文信息。
8、GPT特性自回归语言模型,单向处理文本,生成能力强应用场景文本生成任务BERT特性双向处理技术,捕捉上下文信息,包含Masked LM和Next Sentence Prediction任务应用场景语义理解任务ALBERT特性继承BERT框架,参数分解共享,移除NSP,采用SOP,提高稳定性和效率应用场景各种NLP任务。
9、GPT的架构相较于传统Transformer主要区别在于取消了编码器,仅保留解码器结构,使得模型更专注于预测文本生成任务在训练过程中,GPT通过预训练和细调FineTuning策略实现模型性能提升,其中预训练任务是基于下一个词预测的目标,相较于BERT的完形填空任务更为复杂训练范式中,GPT通过标准的语言模型任务。
10、GPT通过在大量文本数据上进行预训练,能够生成类似人类的文本,具备强大的语言理解和生成能力BERTBidirectional Encoder Representations from Transformers,一种基于自注意力机制的双向预训练语言模型,能够同时捕捉左右上下文信息,拥有卓越的语言理解能力VGGVisual Geometry Group,一种基于卷积神经网络。
11、从BERT到GPT4的Transformers模型回顾如下BERT基于Transformer编码器特点采用wordpiece tokenization,词汇量为30K通过Masked Language Modeling和Next Sentence Prediction两个任务进行训练在MLM中,模型需预测被屏蔽的单词NSP任务预测文本序列是否连贯RoBERTa基于BERT的增强版本特点专注于MLM。
12、在微调阶段,模型能够通过特定任务的数据集进行进一步优化,从而实现更好的性能GPT与BERT的对比揭示了二者在架构与预训练任务上的差异,GPT采用Transformer Decoder层,而BERT则基于Encoder层对比之下,GPT在性能上的不足主要归因于其预训练任务的难度与数据集规模GPT2进一步提升了数据量与模型大小,并。
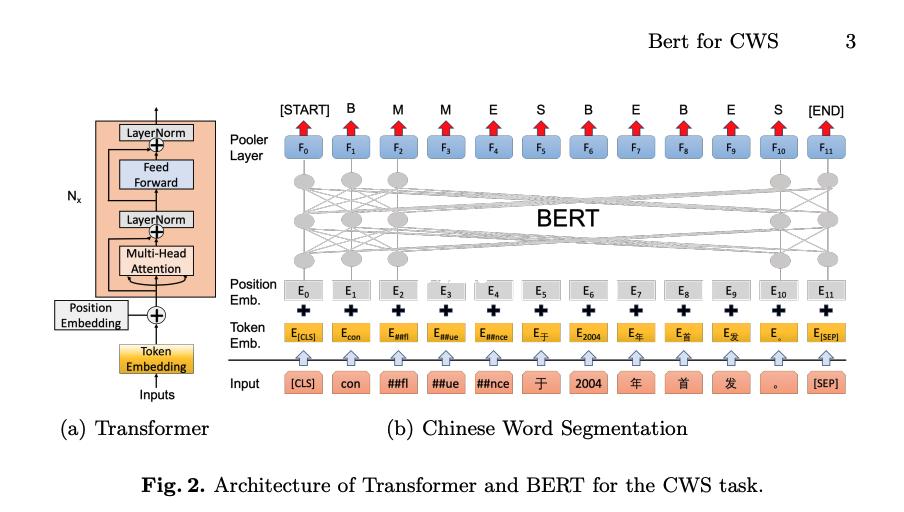
13、Transformer 模块的演进包括编码器和解码器模块编码器模块可以处理不同长度的输入序列,而解码器模块在自注意力层上与编码器模块有差异,仅关注编码器输出的片段GPT2 采用的是不包含编码器的架构,专注于自回归机制理解 GPT2 和 BERT 的区别在于自注意力机制的实现GPT2 的带掩模自注意力层。
14、在自然语言处理领域,BERTBidirectional Encoder Representations from Transformers是基于Transformer架构的预训练模型,相较于GPT,它采用了双向编码,不仅能捕捉上下文信息,还能减少训练所需的参数数量BERT在预训练阶段通过两种方式完成掩码语言模型Masked Language Model,MLM和下一句预测Next。
15、大模型的训练方法多样,如基于Transformer架构的BERT和GPT系列模型,训练方式区别明显BERT通过在句子中随机掩盖一个词元并预测下一句进行训练,GPT系列则采用自回归方式预下一词元ZhipuAI的GLM系列模型结合了这两种方式,随机MASK输入中连续跨度的token,并使用自回归空白填充方法重建这些内容现今大模型。








还没有评论,来说两句吧...