

impala和hive的区别主要有以下几个1执行计划不同Impala把执行计划表现为一棵完整的执行计划树impalahive区别,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的mapreduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffleHive的执行计划分成mapshufflered。
Impala同样采用了独立的执行器,它专为SQL查询而设计,特别适用于大规模数据分析场景Impala的性能在某些情况下甚至能超过Hive,尤其是在处理实时数据和交互式查询时Impala的优化器能够生成高效的执行计划,提高查询效率综上所述,PrestoImpalaHive和Spark SQL在执行框架核心设计理念以及目标应用场。
优化方向Impala更注重内存利用,减少中间结果的磁盘存储,执行计划更高效数据流Impala采用拉取方式,而Hive通常采用推送方式应用场景Hive更适用于复杂的批处理任务,而Impala则适用于实时分析性能优化建议部署策略合理部署Impala组件,以优化资源利用和查询性能内存限制根据实际需求调整内存限制。
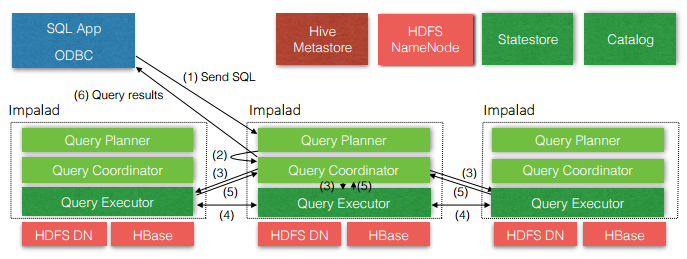
处理方式不同30ms15s近实时Hadoop生态系统里还在不断的有新组件加入例如ApacheKuduParquetbeam等,每一个组件有不同的功能在现实场景中,用户往往需要同时部署很多Hadoop工具来解决同一个问题,这种架构称为混合架构用户使用HBase对于大量小规模查询计算,而利用HDFSParquetImpalaHive来对超。
数据库和数据仓库的主要区别体现在设计目的数据存储方式数据处理方式及应用场景等方面数据库主要用于支持企业的日常业务操作,如订单处理库存管理等,它面向事务处理和业务操作,数据以表格形式存储,通常包含当前业务数据数据库主要用于联机事务处理OLTP,实时性要求高,数据需要频繁更新,适用于。
简单来说云计算是硬件资源的虚拟化,而大数据是海量数据的高效处理虽然从这个解释来看也不是完全贴切,但是却可以帮助对这两个名字不太明白的人很快理解其区别当然,如果解释更形象一点的话,云计算相当于我们的计算机和操作系统,将大量的硬件资源虚拟化后在进行分配使用可以说,大数据相当于海量。
处理实时计算属于一类的,即计算在数据变化时,都是在数据的计算实时性要求比较高的场景,能够实时的响应结果,一般在秒级,Yahoo的S4,twiter的storm都属于流处理和实时计算一类的。
通过时间片拆分数据,以批处理方式处理交互式查询技术,如ImpalaKuduHiveSpark SQLGreenplum MPP,用于商业智能领域,支持快速分析批处理技术如MapReduceSpark,前者通过自动拆解计算为Map和Reduce阶段,后者提供更通用高效的数据集操作,如RDD抽象,支持多种转换和动作操作。
这一点,类似于传统农贸市场与超市的区别市场里面,白菜萝卜香菜会在一个摊位上,如果它们是一个小贩卖的而超市里,白菜萝卜香菜则各自一块也就是说,市场里的菜数据是按照小贩应用程序归堆存储的,超市里面则是按照菜的类型同主题归堆的“与时间相关”数据库保存信息的。
1,大数据big data,指无法在一定时间范围内用常规软件工具进行捕捉管理和处理的数据集合,是需要新处理模式才能具有更强的决策力洞察发现力和流程优化能力的海量高增长率和多样化的信息资产 2,大数据与云计算的关系就像一枚硬币的正反面一样密不可分大数据必然无法用单台的计算机进行处理。

事实上这两个学科也都在探索隐藏在数据中的新内涵虽然二者都对数据科学这一新生领域作出了令人瞩目的贡献,impalahive区别他们并非完全独立的数据的增长不仅体现在其规模上,还体现在我们对数据这个词定义的延伸上举个例子,文本和图像已成为日益常见的数据形式并被纳入分类及风险建模等分析范畴中对数据定义的延伸。
一云计算与大数据侧重点不同 大数据指无法在一定时间范围内用常规软件工具进行捕捉管理和处理的数据集合,是需要新处理模式才能具有更强的决策力洞察发现力和流程优化能力的海量高增长率和多样化的信息资产云计算是基于互联网的相关服务的增加使用和交付模式,通常涉及通过互联网来提供动态易扩展且。
但是处理效率很慢,绝对和传统的数据库的处理效率有天壤之别,所以人们又在想怎样在大数据处理上不只是操作方式类SQL,而处理速度也能“类SQL”,Google为我们带来了DremelPowerDrill等技术,ClouderaHadoop商业化较强的公司,Hadoop之父cutting就在这里负责技术领导的Impala也出现了。
即席查询一般是通过SQL完成,最大的难度在于响应速度上,使用Hive有点慢,目前我的解决方案是SparkSQL,它的响应速度较Hive快很多,而且能很好的与Hive兼容 当然,impalahive区别你也可以使用Impala,如果不在乎平台中再多一个框架的话 OLAP 目前,很多的OLAP工具不能很好的支持从HDFS上直接获取数据,都是通过将需要的数据同步到关系型。








还没有评论,来说两句吧...