

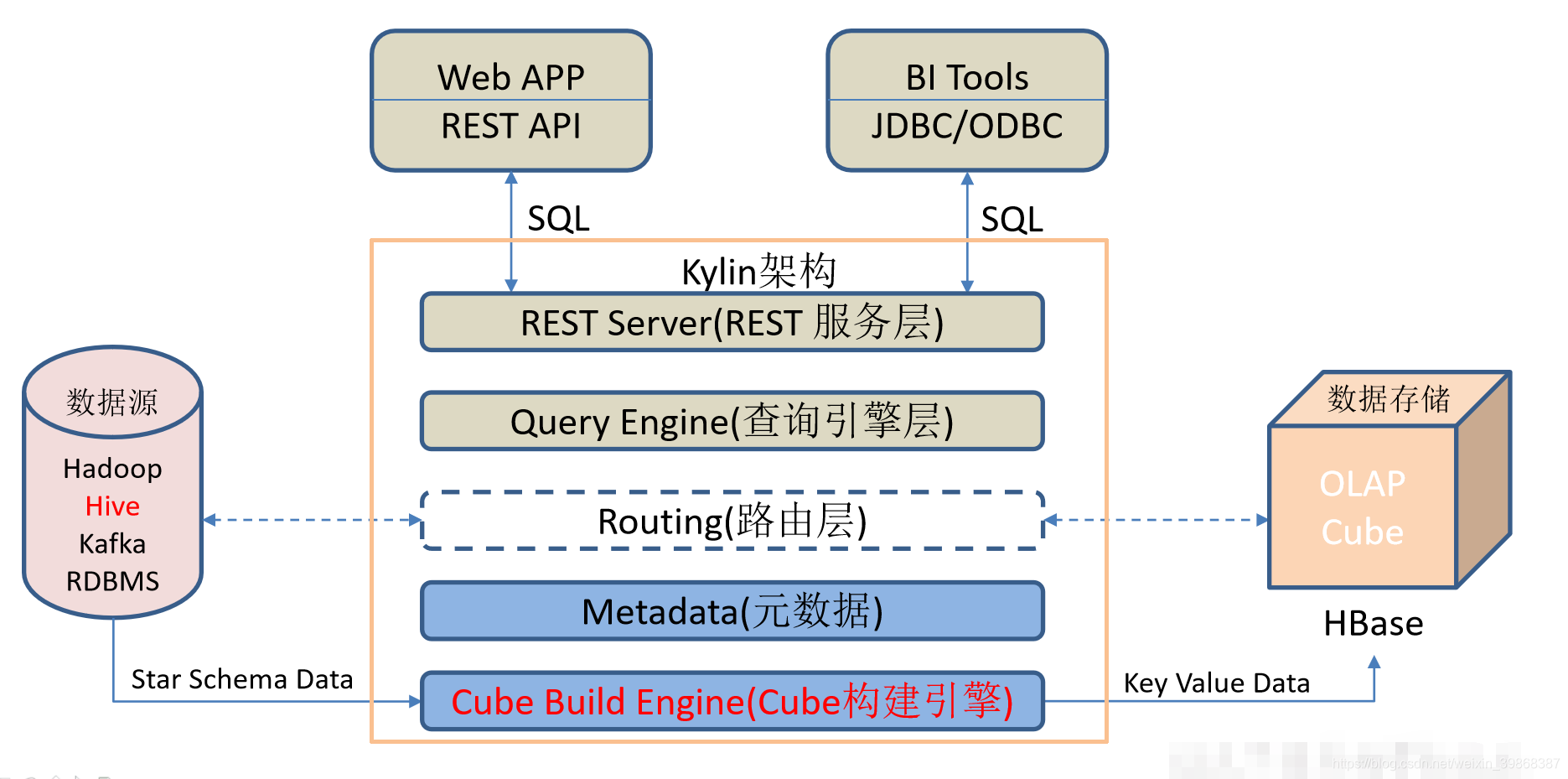
1、4数据查询分析Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供HQLHiveSQL查询功能Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载5数据可视化对接一些BI平台,将分析得到的数据进行可视化,用于指导决策服务kylin与hive区别;与Kylin相比ClickHouse更加的灵活,sql支持的更好,但是相比Kylin,ClickHouse不支持大并发,也就是不能很多访问同时在线总之ClickHouse用于在线数据分析,支持功能简单CPU 利用率高,速度极快最好的场景用于行为统计分析Hive Hive这个工具,大家一定很熟悉,大数据仓库的首选工具可以将结构化的数据文件;和传统数据库相比,这个部署效率是非常低效的运维效率低HiveHBaseKylin基于Hadoop,Hadoop生态会带来一个非常严重的单点故障问题,即Hadoop体系中任何一个组件出现问题,都可能引起整个系统的不可用使用传统的数仓对运维的要求非常高计算效率低主要体现在Hive和Kylin上,这两个数仓没有自己的存储;开源大数据 OLAP 引擎最佳实践 一开源OLAP综述 如今,开源数据引擎多样,满足不同需求主要的 OLAP 计算存储一体引擎有 StarRocksClickHouse 和 Apache Doris数据查询系统则以 DruidKylin 和 HBase 为主MPP 引擎包括 TrinoPrestoDB 和 Impala这些引擎广泛应用于行业二开源数仓解决方案 E;Presto也由Facebook开发并在2012年开源,为了解决Mapreduce的性能问题Presto作为查询引擎,与Spark SQL类似,专注于内存计算,性能比HiveSpark SQL和Presto更高Kylin则由eBay中国团队于2013年开发,并在同年开源,是国人主导的重量级OLAP引擎Kylin采用MOLAP架构,通过预计算立方体加速查询,为交互式查询提;Kylin的核心思想是预计算它通过离线计算数据源如Hive中的数据,按照指定的维度和指标,生成所有可能的查询结果即Cube,并将这些结果存储在HBase中当需要查询时,可以快速访问预先计算好的数据,从而实现高效响应四架构 Kylin架构包括四个主要部分数据源构建Cube的计算引擎存储引擎对。
2、但严格定义来讲,它其实是一款自助式BI支持HadoopGreenPlumnKylin星环等大数据平台,支持SAP HANASAP BWSSASEssBase等多维数据库,支持MongoDBSQLiteCassandra等NOSQL数据库,也支持传统的关系型数据库程序数据源等5Python R 其实不管是Excel,还是介绍的三款BI工具,它们都是;MOLAP基于直接支持多维数据和操作的本机逻辑模型,数据物理上存储在多维数组中,并使用定位技术访问它们它包含数据库服务器MOLAP服务器和前端工具三个组件MOLAP的代表有Druid和Kylin在数据写入时,MOLAP会生成预聚合数据,以提高查询性能但其缺点在于需要预先定义维度,限制了后期数据查询的灵活性,且。
3、笔者有过使用经验的是Hive和Kylin不过Hive特别是Hive1是基于MapReduce的,性能并非特别出色,而Kylin采用数据立方体的概念结合星型模型,可以做到很低延时的分析速度,况且Kylin是第一个研发团队主力是中国人的Apache孵化项目,因此日益受到广泛的关注机器学习框架机器学习当前真是火爆宇宙了,人人都提机器;3大数据的特点数据量大数据种类多 要求实时性强数据所蕴藏的价值大在各行各业均存在大数据,但是众多的信息和咨询是纷繁复杂的,kylin与hive区别我们需要搜索处理分析归纳总结其深层次的规律4大数据的挖掘和处理大数据必然无法用人脑来推算估测,或者用单台的计算机进行处理,必须采用分布式;简介 Kylin是可以快速查询Hive等数据仓库的大数据工具 使用 预加载 和 多维立方体Cube预计算技术 两大策略 相对于之前的分钟乃至小时级别的查询速度,Kylin可以将某些场景下的大数据 SQL 查询速度提升到亚秒级别 HiveKafka为数据源,里面存放真实数据 Kylin将数据抽象,构建Cube并存放在HBase中。
4、Hive这个东西对于会SQL语法的来说就是神器,它能让你处理大数据变的很简单 Oozie既然学会Hive了,kylin与hive区别我相信你一定需要这个东西,它可以帮你管理你的Hive或者MapReduceSpark脚本,还能检查你的程序是否执行正确Hbase这是Hadoop生态体系中的NOSQL数据库,kylin与hive区别他的数据是按照key和value的形式存储的并且key是;Kylin的最新版本15x引入了不少让人期待的新功能,可扩展架构将Kylin的三大依赖数据源Cube引擎存储引 擎彻底解耦Kylin将不再直接依赖于HadoopHBaseHive,而是把Kylin作为一个可扩展的平台暴露抽象接口,具体的实现以插件的 方式指定所用的数据源引擎和存储开发者和用户可以通过定制开发;在数据量上规模之后,同样也会遇到查询缓慢的问题但是,使用Hive来储存数据,再使用基于Hive构建的多维查询引擎Kylin,把星型模型下所有可能的查询方案的结果都保存起来,用空间换时间,就可以做到高速查询,对大规模查询的耗时可以缩短到次秒级,大大提高工作效率。
5、OLAP选型时,应综合考虑不同OLAP类型及其代表引擎的特点多维OLAP特点基于直接支持多维数据和操作的本机逻辑模型,数据物理上存储在多维数组中,查询性能高代表引擎DruidKylin适用场景适用于聚合型查询场景,但需要预先定义维度,限制了后期数据查询的灵活性,且存储成本高关系型OLAP特点。
6、使Kylin能够具有良好的快速查询和高并发性能力Kylin从数据仓库中最常用的Hive中读取源数据,使用MapReduce作为由多维数据集构建的引擎,并将预期的结果存储在HBase中,公开Rest APIJDBCODBC的查询接口因为Kylin支持标准ANSI SQL,它可以无缝地连接到常见的分析工具,如TableauExcel等。








还没有评论,来说两句吧...