

新的问题出现unicode与ascll区别了unicode与ascll区别,如果统一成unicode编码,乱码问题从此消失了但是如果你写的文本基本上都是英文的, 用Unicode编码比ascii编码需要多一倍的存储空间,在存储和传输上十分不方便 utf8应用而生,它是一个quot可变长的编码方式quot,如果是英文字符,则采用ascii编码,占用一个字节 如果是常用汉字,就占用;这是与ASCII码的主要区别小写字母a的Unicode编码与ASCII码相同,都是97ASCII码系统基于拉丁字母,主要用于表示现代英语和其unicode与ascll区别他西欧语言,是国际上广泛采用的信息交换标准,符合ISOIEC646国际标准在ASCII码表中,大写字母与对应的小写字母之间相差32的码值,而数字0到9的ASCII码值分别为48到57。
英文字符 quotzhouquot 在 utf 编码中可以显示为原本的字符,这是因为 utf 编码兼容 ascii 码,对能够使用 ascii 编码的字符以字符形式显示除了 utf8 编码,还有 utf16,utf16LE,utf16BE,utf32,utf32LE,utf32BEutf16 和 utf32 与 utf8 的不同之处在于字节序大端序和小端序;但是如果每个国家都这么搞那不就乱套了嘛,于是Unicode就应运而生了Unicode Unicode是个符号集,与ASCII类似,只不过容量要大得多,可以理解成一张表,为世界上的每一个字符指定了一个惟一的二进制代码,但是它并没有规定这个二进制代码如何存储,于是乎UTF8UTF8without bomUTF16UTF。
这个方法是有缺陷的,因为各个国家地区定义的字符集有交集,因此使用GB2312的软件,就不能在BIG5的环境下运行显示乱码,反之亦然为了把全世界人民所有的所有的文字符号都统一进行编码,于是制定了UNICODE标准字符集UNICODE 使用2个字节表示一个字符unsigned shor intWCHAR_wchar_tOLECHAR;1 ASCII编码是最早的字符编码标准,它使用8位1字节来表示128个不同的字符,包括控制字符和基本文本字符2 Unicode编码是为了克服不同字符编码之间的兼容性问题而提出的全球性标准它使用16位2字节来表示字符,几乎包含了世界上所有书写系统的字符3 GBK编码是中国特有的双字节字符集,它。
ASCII码使用一个字节编码,所以它的范围基本是只有英文字母数字和一些特殊符号 ,只有256个字符在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符在基本多文种平面英文为 Basic Multilingual Plane,简写 BMP它又简称为“零号平面”, plane 0里的。
ascii unicode utf8 gbk的区别
1、UnicodeASCIIUTF8编码之间的区别如下1 ASCII编码 定义ASCII是一种基于拉丁字母的字符编码系统,主要用于文本电子交换 字符范围它包含了英文字母数字标点符号和一些特殊符号,总共128个字符 字节长度每个字符使用7位二进制数表示,但为了与8位字节兼容,最高位通常设置为0,因此实际。
2、1 Unicode编码和ASCII码都是对字符进行编码的方式,这是它们的共同之处2 Unicode编码在ASCII码的基础上进行了扩展,能够同时支持多种语言,包括拉丁语和本地语言换句话说,Unicode编码兼容ASCII码,但它包含了更多的字符集,这是它们的主要区别。
3、个字符2编码的范围不同每个ASCII字符对于英文而言,一般只。
4、了解字符编码的基础,ASCIIUnicode和UTF8是必不可少的ASCII,起源于1963年的电报码扩展,最初包含128个字符,主要用于英文显示,后续的EASCII扩展了8位编码,支持部分西欧语言ASCII中的转义字符是电传设备简化的输入规则,如 rn 会被计算机转换为CRLF控制字符Unicode是全球统一的字符编码标准。
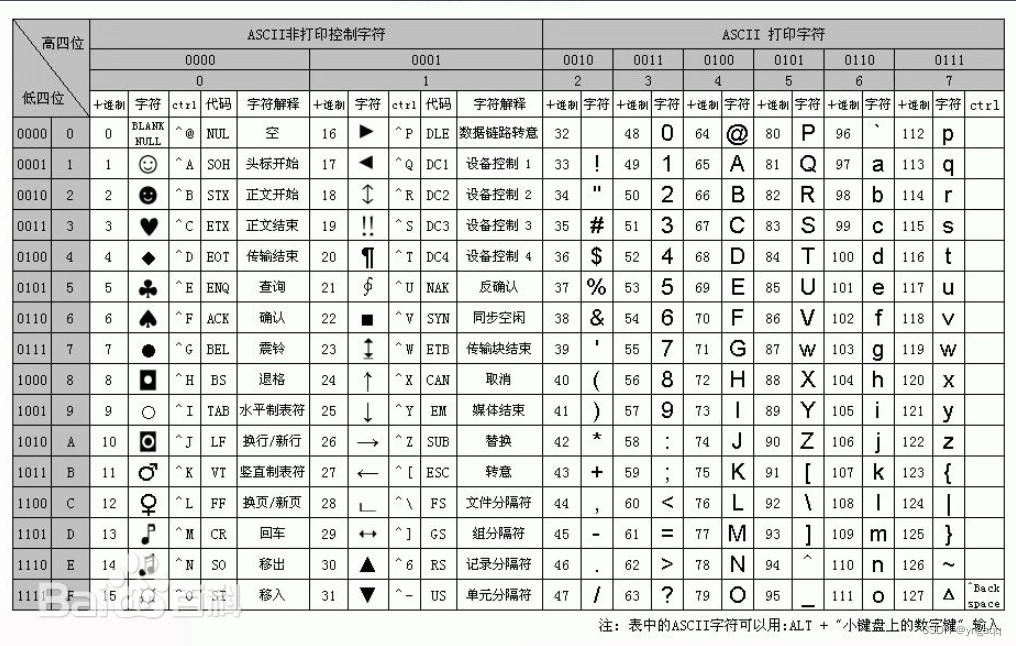
unicode和ascii对应吗
ASCII就是编码英文的26个字母和一些常见的符号,之后扩展了一半总之是一个字节来做编码,大于128的部分是一些特殊符号但ASCII是无法编码别的东西的,比如说是不存在“中文的ascii码需要2个字符”这种说法的ASCII就只有一个字节Unicode是足够编码地球上所有的语言了,所以ASCII中所能表示的,Unicode。
繁体以及其他语言,如英文日文和韩文简而言之,ASCII主要用于英文字母数字和一些特殊符号,字符范围有限Unicode则能表示全世界范围内的字符,适用于多种语言GBK专注于汉字编码,采用双字节编码而UTF8则是一种通用的字符编码,能够在网页上实现多种语言的兼容显示。
如果定义了_unicode,那么预处理的结果就是wchar_t retval,szstringretval = _wcsrevszstring如果都没有定义,那么将使用单字节的ascii编码char retval,szstringretval = strrevszstring所以说为了考虑将来程序的可移植性,以及程序的国际化,最好对字符的定义使用_tchar,并且 让所有对字符。
ASCII码和Unicode码的不同之处在于,ASCII码使用7位二进制数编码,可以表示128个字符,而Unicode码使用两个字节编码,可以表示更多的字符Unicode码可以表示包括中文日文韩文在内的多种语言字符,而ASCII码仅能表示英文字符虽然Unicode码与ASCII码不兼容,但在实际应用中,可以通过转换实现两种编码之间。
1 ASCII编码主要用于英文字母数字和特殊符号,它使用一个字节存储,因此只包含256个字符2 Unicode编码使用十六进制数表示字符,通常用“U+”加上一组十六进制数字基本多文种平面BMP内的字符使用四位十六进制数表示,超出BMP的字符则需要五位或六位十六进制数Unicode 30版本之前,编码方法。








还没有评论,来说两句吧...