

梯度下降和随机梯度下降梯度下降区别的区别 1标准梯度下降是在权值更新前对所有样例汇总误差梯度下降区别,而随机梯度下降的权值是通过考查某个训练样例来更新的2在标准梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算3标准梯度下降,由于使用真正的梯度,标准梯度下降对于每一次权值更新经常使用比随机梯度下降。
批量梯度下降随机梯度下降和小批量梯度下降的区别如下批量梯度下降 特点在每一次迭代时使用所有样本进行梯度更新 优点梯度估计准确,方差较低,计算过程包含向量化操作,效率较高 缺点计算量大,在处理大规模数据时性能受限随机梯度下降 特点每次迭代仅使用一个样本更新参数 优点迭。
2 梯度下降法轻盈的步伐 以一阶泰勒展开为指导,梯度下降法如同舞者,沿着误差梯度的反方向逐步迭代但它可能会陷入局部最小值的“锯齿”路线,游走在全局最优解的边缘3 高斯牛顿法精简的策略 高斯牛顿法旨在最小化二乘误差,避免了海塞矩阵的繁琐计算然而,在矩阵奇异时可能会稳定性下降。
区别在于 导数,指的是一元函数中,函数 在某一处沿 轴正方向的变化率 偏导数,指的是多元函数中,函数 在某一点处沿着某一坐标轴 正方向的变化率方向导数的定义如下 在前面导数和偏导数的定义中,均是沿坐标轴正方向讨论函数的变化率那么当我们讨论函数沿任意方向的变化率。
两者的区别梯度下降法是沿着梯度的负方向最小化目标函数共轭方向法是把x表示成相对于系数矩阵A共轭的一组基向量的线性组合,然后每次沿着共轭方向一维最小化目标函数梯度下降法就是常说的最速下降法,考虑一个n维空间,我任意选取一个初始点,然后每次迭代的时候都以该点的负梯度方向如果目标函数。
梯度下降法和随机梯度下降法在计算量方面有着显著的不同具体来说,最小二乘法通常涉及计算矩阵的逆,这在面对大规模数据时往往需要大量的计算资源,且数值稳定性问题也较为突出,比如希尔伯特矩阵求逆几乎是不可能完成的任务相比之下,梯度下降法虽然在迭代次数上可能较高,但整体计算量相对较小,尤其。
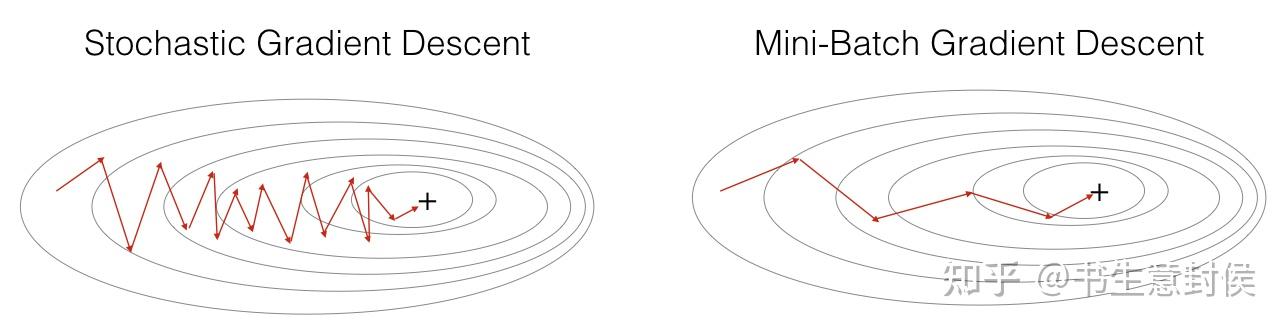
在优化机器学习模型的过程中,三种常见的方法批量梯度下降随机梯度下降和小批量梯度下降,主要区别在于每次参数更新时数据集的使用策略批量梯度下降,犹如一个深思熟虑的决策者,每次迭代都会遍历整个数据集,细致考量每一步,尽管决策稳健,但处理大规模数据时可能会显得效率较低,就像一个深思熟虑的。
Stochastic Gradient Descent和Gradient Descent的主要区别在于数据点的选择和计算效率解释如下梯度下降法是一种用于优化损失函数的方法,通过计算整个数据集上的损失函数的梯度来更新模型的参数这意味着在每一步的迭代中,都会使用整个数据集来计算梯度,这种方法在数据集较大时非常耗时且计算资源消耗大。
主要区别在于方向选择策略梯度下降法直接利用当前点的梯度方向,可能在某些情况下导致收敛速度较慢或不收敛而共轭梯度法则通过选择一组共轭方向,理论上能够更有效地找到全局极小值,展现出较好的收敛性能在具体应用时,应根据优化问题的特点和需求选择合适的方法。
2 与梯度下降的区别传统的梯度下降法是在整个数据集上计算损失函数的梯度,然后更新模型参数而SGD则是随机选择一个样本或者一个小批量样本计算梯度,然后更新模型参数由于每次只使用一部分数据,SGD的计算效率更高,可以处理大规模数据集,并且在高维空间中表现良好3 应用场景SGD广泛应用于各种。
当优化神经网络模型的权重和偏差参数时,选择合适的优化算法至关重要本文将带梯度下降区别你理解梯度下降随机梯度下降和Adam方法在模型训练中的作用和区别优化算法的目标是通过调整模型参数,最小化损失函数,如梯度下降通过梯度指向的反方向更新参数,试图找到局部最优解梯度下降是基础算法,但批量梯度下降在处理。
迭代法,即在每一步update未知量逐渐逼近解,可以用于各种各样的问题包括最小二乘,比如求的不是误差的最小平方和而是最小立方和梯度下降是迭代法的一种,可以用于求解最小二乘问题线性和非线性都可以高斯牛顿法是另一种经常用于求解非线性最小二乘的迭代法一定程度上可视为标准非线性。
因而这样的计算方法有时不值得提倡相比之下,梯度下降法虽然有一些弊端,迭代的次数可能也比较高,但是相对来说计算量并不是特别大而且,在最小二乘法这个问题上,收敛性有保证故在大数据量的时候,反而是梯度下降法 其实应该是其他一些更好的迭代方法更加值得被使用。

1stochastic gradient descent随机梯度下降 2gradient descent梯度下降 而stochastic随机 形容词 random随机, 任意, 乱, 随便, 轻淡, 胡乱的 stochastic随机 1Stochastic and mathematical models随机和数学模型2In this paper, a numerical method for structure stochastic response analysis is。
LMS算法的滤波能力在一定程度上受限于相关矩阵R和互相关矩阵p的瞬时估计,然而通过内置的反馈机制,R和p的估计在自适应过程中取时间平均,有助于提升算法的性能梯度自适应格型滤波算法GAL是基于随机梯度下降法的另一种自适应滤波技术GAL算法与LMS算法的主要区别在于引入了联合估计,通过两级结构。
在深度学习的探索中,优化算法扮演着关键角色其中,梯度下降算法是最基础的,但工程实践中,我们更多地关注BGD批量梯度下降SGD随机梯度下降和MBGD小批量梯度下降这三种变形它们的区别在于数据量对梯度计算的影响,平衡了精度与效率BGD使用全部数据,保证了准确性但计算耗时,SGD每次只用一。
梯度提升树的基本原理 知识点GBDTCART 问题1GBDT基本原理是什么分析与解答GBDT是boosting中算法,基本思想根据当前模型损失函数负梯度信息训练新弱分类器,累加到现有模型中算法使用决策树作为弱分类器,训练过程利用残差梯度提升和梯度下降的区别和联系 知识点GBDT梯度下降 问题2梯度提升。
优化器是基于梯度下降算法,通过调整模型参数以最小化损失函数SGDBGDMBGD是基于梯度下降的不同实现,区别在于更新参数的频率与数据量Momentum和NAG在传统梯度下降的基础上引入动量概念,以平滑梯度更新,减少震荡AdagradAdadeltaRMSprop则是自适应学习率优化器,能够根据不同参数动态调整学习率。








还没有评论,来说两句吧...